Video Summarization of Fixed Video Surveillance Cameras
Overview
Video summarization techniques aim to reduce the amount of data available in a video, by condensing temporal information. We focus here on 2 different approches:
- Video Synopsis, where the objective is to merge non-intersecting trajectory onto the same frames
- Keyframe Selection, where the objective is to keep the interesting frames of a video
Video Synopsis
The objective of automatic video summarization is to provide users of video monitoring systems with consise summaries of what has been observed by a surveillance camera during a long period of time. In some cases, when the scene is usually quiet, simple motion detection would suffice, but in most cases such simple approach will still produce a too long summary. In this project, we aim at obtaining better summaries by combining the different moving objects and display them together, inside the same frames, whenever possible.
The following image represents an overview of the given approach.
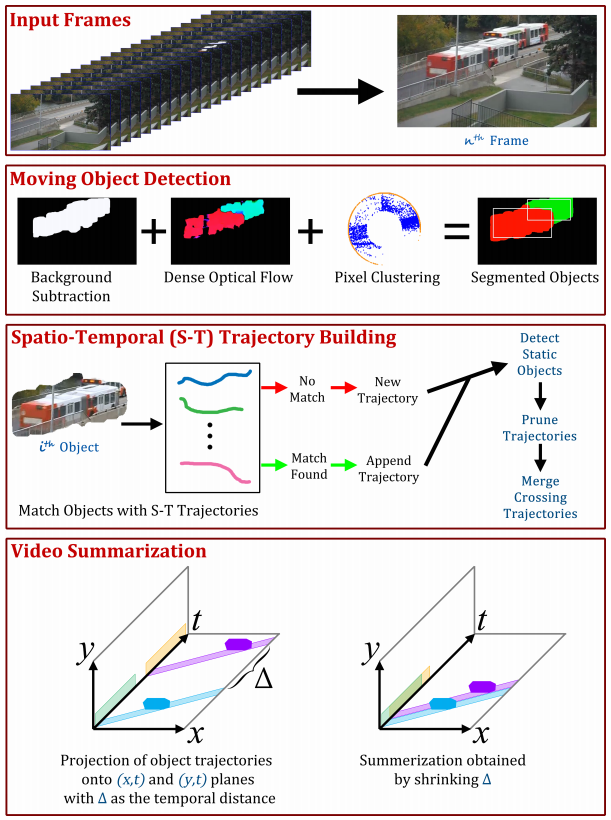
More details on the model can be found on the paper here, as well as on the associated poster here.
This is the original video
|
|
Simple solution 1: using motion detection
|
|
Simple solution 2: fast-forwarding
|
|
Our solution: merging moving objects
|
|
Our solution: merging moving objects with collisions
|
|
Keyframe Selection
Keyframe selection aims at collecting the most interesting/representative frames of a video. As opposed to video synopsis, no modification is made on the frames.
Such method can be divided in 2 parts:
- Feature Extraction, which consists avec creating a temporal curve from multiple features (such as saliency map, detection map, etc.). This step aims to create a 1-dimension curve from the video.
- Keyframe selection, which will use the previous 1-dimension curve to find which frames can be selected for the final result.
This is the original video
|
|
Solution 1: using only saliency
|
|
Solution 2: using only detection label
|
|
Solution 3: using only detection position
|
|
Solution 4: using all features
|
|
Navigation
Participants
Video Synopsis
- Marc Decombas
- Kelvin Moutet
- Po Kong Lai
Keyframe Selection
- Pierre Marighetto
- Max Cohen