SEG-2506 "Construction de logiciels"
La concurrence
Lectures supplémentaires:
- [Sebesta] chapître 12 (voir notes imprimées en vente) SVP, lire Sebesta 12.1 (Introduction), 12.2
(Introduction to subprogram-level concurrency), 12.3 (Semaphores), 12.4
(Monitors), and 12.7 (Java threads).
Concurrence en matériel et logiciel
Concurrence matériel
Un processeur d'un ordinateur exécute une instruction après
l'autre. Il n'y a pas de parallélisme. Si nous avons plusieurs processeurs
tournants en parallèle (soit à l'intérieur du même
ordinateur, soit dans différents ordinateurs) nous avons une des formes
du parallélisme ("concurrency" ou "parallelism"). Cette forme de parallélisme
réalisée au niveau matériel est appelée parallélisme
physique ou concurrence matériel. Le parallélisme physique est lié aux ordinateurs
à architecture parallèle. Différentes méthodes
ont été inventées pour construire des architectures
parallèles (avec plusieurs processeurs) pour exécuter de façon
efficace plusieurs tâches en parallèle. On peut classifier ces
méthodes ainsi:
- Un ordinateur normal contient au moin un CPU et plusieurs unités de traitement périphériques qui s'occupent des entrée/sorties avec le monde extérieur, tel que affichage vidéo, entrée-sortie de son, accès aux disques, etc. Aussi l'horloge de l'ordinateur est une unité physique séparée qui fonctionne en parallel avec le CPU - elle est utilisée par le céduleur du système d'exploitation pour allouer le CPU pour des périodes de temps aux différents programmes actifs (voir ci-dessus).
- Différents schéma ont été développés pour construire des ordinateurs avec plusieurs CPU. Le but est de pouvoir exécuter d'une façon efficace plusieurs tâches de calcul en parallel. Ils peuvent être classifiés comme suit:
- SIMD ("single instruction - multiple data", une instruction/plusieurs
données): Il s'agit d'ordinateur avec plusieurs processeurs
travaillant sur des données différentes mais exécutant
tous la même séquence d'instructions. Les ordinateurs
vectoriels appartiennent à cette classe.
- MIMD ("multiple instructions - multiple data" plusieurs
instructions/plusieurs données): Ici les différents
processeurs exécutent chacun une séquence d'instructions
différente (et travaillent sur différentes données).
Cette classe peut-être encore subdivisée comme suit:
- architecture par mémoire partagée: Dans ce cas, tous les processeurs
accèdent la même mémoire (physique), mais pas forcément les mêmes données.
Dans ce cas, il est simple de partager des données entre les différents
processus exécutés sur chaque processeurs.
- architecture distribuée: Dans ce cas, chaque processeurs a sa propre
mémoire (physique; chaque processeur est en fait presque un ordinateur
complet). Le partage de données entre les processus (sur leurs différents
processeurs) est moins efficace. Il est habituellement réalisé par un
réseau qui connecte tous les processeurs.
- Parallélisme pour l'exécution des instructions: Réalisé par un
seul processeur qui est constitué de plusieurs composantes
fonctionnant elles-mêmes en parallèle. Le processeur
est organisé de façon à ce que plusieurs instructions
(machine) puissent être exécutées en parallèle,
habituellement par une exécution en "pipeline" où
les instructions passent successivement au travers des différentes
composantes du processeur pour être exécutées
entièrement. Chaque composante effectue un aspect spécifique
de l'instruction. On peut rapprocher cela d'une décomposition
des instructions en micro-instructions.
Concurrence en logiciel
Dans le manuel, Sebesta distingue les quatre niveaux de concurrence
suivants:
- Parallélisme d'instructions: Ceci est de la concurrence au niveau du matériel, appellé "Parallélisme pour l'exécution des instructions" ci-haut.
- Parallélisme de "statements": Dans ce niveau, les
instructions d'un programme (langage de haut niveau: "statements")
sont exécutées en parallèle sur un ordinateur
à architecture parallèle (parallélisme physique).
En général, on considère ici un langage de programmation
conventionnel (séquentiel, i.e. non parallèle) comme
Fortran ou C. Certains compilateurs sont capables de déterminer
automatiquement quelles instructions (de haut niveau: "statements")
sont indépendantes les unes des autres et peuvent être
exécutées en parallèle sans modifier le résultat
du programme. Ces compilateurs peuvent aussi prendre en compte l'architecture
parallèle particulière sur laquelle le programme devra
s'exécuter pour générer du code optimisé
pour cette architecture. Note: Le programmeur n'est normalement pas impliqué pour ce type de concurrence, puisqu'il est normalement traité automatiquement par le compilateur optimisant.
- Parallélisme d'unité ("unit concurrency"): Il
s'agit d'unités qui sont définies dans le langage de
programmation comme pouvant être exécutées en
parallèle. Les langages de programmation avec "unités
parallèles" permettent au programmeur de concevoir des programmes
incluant des parties parallèles. La parallélisme du
programme dépend de l'application. Un domaine typique où
cela est utile est la simulation (ex: contrôle de systèmes
ou systèmes de transport) où les objets simulés
évoluent en temps réel et en parallèle. Ce niveau
est aussi appelé parallèlisme logique. Contrairement
au parallélisme physique, il n'implique pas que les unités
logiquement parallèles soient physiquement exécutées
en parallèle. souvent elles sont exécutées de
façon "inter-croisée" ("interleaved") (v. "partage
de temps" ou "time sharing" ci-dessous). Note: Au lieu de "unités",
on parle aussi souvent de processus ("process"), "thread",
ou simplement "concurrent statement"). Note: Ce type de concurrence doit être compris par le programmeur qui utilise un langage de programmation qui supporte des thread concurrents (e.g. Java). Dans ce cours, nous nous intéressons plus particulièrement
à ce type de concurrence.
- Parallélisme de programme: Souvent plusieurs programmes
sont exécutés en parallèle (de façon
"inter-croisée") sur un ordinateur avec un système
d'exploitation qui permet le partage du temps. Le processeur de l'ordinateur
est partagé entre les programmes en leur allouant à
chacun des petites "tranches de temps". L'allocation est faite par
un "scheduler" (v. manuel dur cours). La même technique
de partage de temps est aussi utilisée pour implémenter
le parallélisme d'unités.
Le partage du CPU entre plusieurs threads ou programmes: Chaque système d'exploitation contient un céduleur qui alloue de courtes périodes de temps de CPU aux différents programme actifs dans l'ordinateur. À la fin de chaque période, il détermine quel programme obtiendra le CPU pendant la prochaine période. Un céduleur similaire est inclus dans chaque programme qui supporte à l'intérieur plusieurs threads (unités concurrentes) - ce céduleur déterminera comment la période CPU alloué au programme sera partagée entre les différents threads actifs dans le programme. Par exemple, le programme qui exécute une machine virtuelle Java contient un céduleur pour partager le CPU entre les thread du programme Java (s'il contient des thread en plus du thread main).
Il est à noter que le comportement d'un
céduleur
n'est pas toujours défini dans toutes les détails, e.g. le
céduleur des Threads dans la machine virtuelle qui exécute
le byte-code de Java). On distingue généralement les états suivants d'un
processus (thread, task ...) en relation avec le céduleur (voir diagramme ci-dessous):
- Nouveau (new): processus vient d'être créé
- Exécutant (running): un processeur lui est alloué
qui exécute les instructions du processus
- En attente (ready): le processus est prêt à être
exécuté, mais aucun processeur lui est alloué. Quand le CPU termine avec
le processus exécutant (par exemple, parce que une unité de temps
d'allocution est terminé, et le processus entre l'état en attente)
alors le céduleur choisi un processus dans l'état en attente pour
l'exécution. Lequel est choisi dépend du céduleur; si des priorités sont
définies, elles doivent être prise en compte.
- Bloqué: une entrée/sortie
à été demandé et n'est pas encore complétée, ou le processus a été mis en
attente pour une certain durée de temps
- Terminé (dead): le processus n'a plus aucune
instruction à exécuter
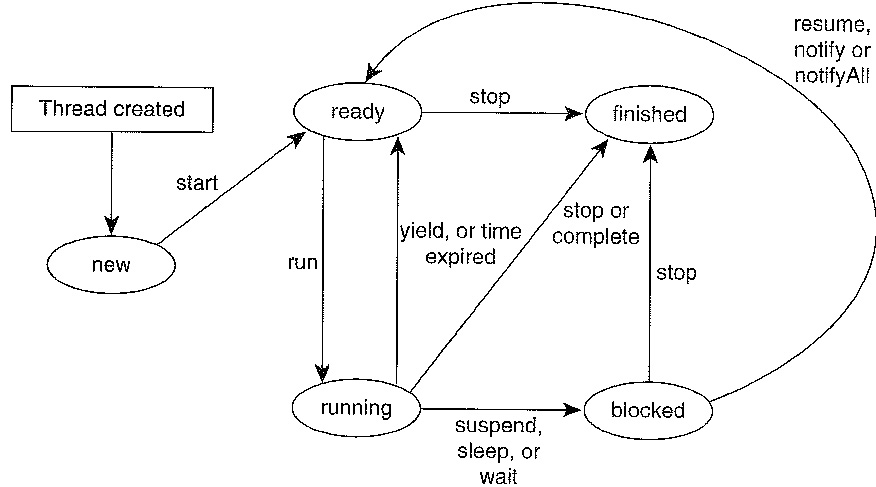
Dépendences entre processus concurrents
Différents formes de dépendence
Dans le cas le plus simple, des processus parallèles font leur
calculs indépendemment les uns des autres. Mais le plus souvent, ils
doivent coordonner leurs efforts ce qui est fait par la communication inter-processus
et la synchronisation. On peut classifier les interactions comme suit:
- Processus disjoints: Ils sont indépendants, il n'y a pas
de synchronisation (excepté peut-être au niveau du
processeur par le partage de temps, mais cela ne concerne pas
le programme qui définit ces processus).
- Synchronisation compétitive: Ils sont logiquement
indépendants l'un de l'autre mais ils partagent certains
ressources en communs (décrit par le programme qui contient
ces processus). Le partagent de ressources nécessite habituellement
une certaine synchronisation des accès (exemple typique: lectures
et écritures dans une base de données partagée,
v. devoir 2).
- Synchronisation coopérative: Les processus dépendent
les uns sur les autres pour pouvoir effectuer leur travail
(le résultat de l'un dépend du résultat de l'autre).
Un exemple typique est le modèle du producteur/consommateur
où on a souvent une queue qui sert a passer les données
(messages) du producteur vers le consommateur (v. les sections 12.4
et 12.7 du livre sur les "moniteurs et parallélisme en Java").
Note: Les synchronisations compétitive et coopérative ou
la communication en général peuvent être réalisées
par des primitives d'échange de messages ou par des variables partagées
(incluant des primitives de base pour la synchronisation qui acceptent une
opération atomique pour tester et mettre-à-jour une variable
("en même temps"). De telles primitives peuvent être fournies
par le système d'exploitation ou par le "hardware" d'un ordinateur
a architecture parallèle. Des exemples de primitives de synchronisation
par variables partagées sont une instruction machine "test and set" ou le concept de sémaphores décrit dans le manuel section 12.3.
La nature non déterministe des systèmes concurrents (rappeller ce que nous avons discuté dans le chapitre 1-3)
Des processus concurrents peuvent donner lieu à un très grand nombre de séquence d'interactions parce que les exécutions des interactions des différents processus peuvent être intercalées de différentes manières. Dans le cas de processus indépendants (comme par exemple pour des régions parallèles dans un diagramme d'état UML) on suppose (par défault) qu'il n'y a pas de relations entre les processus concurrents (pas de communication, pas de ressources partagées, pas de variables partagées). Ceci a l'avantage que le comportement de chaque processus peut être analysé sans considérer les autres processus. Dans ce cas, le nombre de séquences d'exécution est le plus grand, parce que les actions des différents processus peuvent être intercalées de manière quelconque dans la trace d'exécution globale. Un exemple est montré dans le diagramme ci-dessous, où (a) et (b) représentent deux processus indépendants, définis en forme de LTS, et (c) montre le comportement global résultant (obtenu par analyse d'accessibilité - ce qui est simple dans ce cas-ci). Dans cet exemple, on suppose qu'une transition d'un LTSS ne prend pas de temps, donc l'exécution de deux interactions par deux LTS différents peut être considérée comme étant séquentiel (un après l'autre). Quand deux LTS sont indépendant et une interaction est possible pour chaque LTS, alors leur ordre d'exécution n'est pas déterminé; il y a donc du non-déterminism introduit par la concurrence. Ceci est appelé de la sémantique d'interlacement (interleaving semantics).

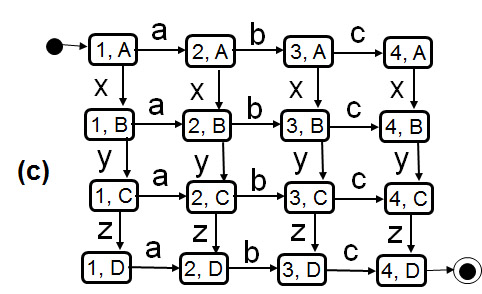
La conclusion principale est le fait que l'on de peut prédire la pas d'exécution qui sera pris par les processus concurrents. Supposant qu'il y a une certaine dépendance entre les deux processus qui amène à certaines difficultés quand la transition z est prise à partir de l'état (3, C), il est très difficile de tester le système pour assurer que cette difficulté est correctement implantée. On ne peut pas contrôler le système pour qu'il prenne un pas particulier. La situation est pire quand on ne sait pas où le problème réside dans l'implantation - les chances d'exécuter la séquence de transitions qui va rencontrer le problème est effectivement très mince lors de tests normaux. Conclusion: Des systèmes concurrents sont très difficile à tester pour vérification. C'est pourquoi on devrait essayer de vérifier de tel systèmes par raisonnement logique.
Quelques notes sur le concept de passages de messages
Un "échange de messages" signifie qu'un processus envoi un message
à un autre processus puis continue son propre travail. Le message
peut prendre un certain temps pour arriver à l'autre processus. Il
peut aussi être stocké dans une file d'attente du processus
destinataire si celui-ci n'est pas prêt à le recevoir. Le message
est "reçu" seulement quand le processus destinataire est prêt.
Ceci décrit un échange de message asynchrone ("asynchronous
message passing"), parce que l'envoi et la réception du message ne
se font pas en même temps (mais la réception doit avoir lieu
après l'envoi !).
L'échange de message asynchrone impose la "synchronisation" suivante
entre les deux processus:
- Opérations d'envoi et de réception bloquantes: Le
récepteur est bloqué si il arrive a un point où
il peut recevoir un message mais aucun message n'a été
émis. L'émetteur pourrait-être bloqué
si il n'y a plus de place dans la file d'attente entre lui et le
récepteur. Cependant la plupart du temps, on suppose
qu'on a des files d'attente de longueur arbitraire et ce problème
ne se produit jamais, l'émetteur n'est donc jamais bloqué.
- Opérations d'envoi et de réception non-bloquantes:
Dans ce cas les opérations d'envoi et de réception
terminent toujours immédiatement en retournant une valeur
qui peut indiquer au récepteur qu'aucun message n'est arrivé
ou que le tampon d'envoi est plain.
Ceci permet au récepteur de tester si un message est
arrivé et de "faire autre chose" sinon.
Dans le cas de l'échange de message synchrone (par exemple comme
réalisé en Ada, v. manuel sections 12.5.1 à 12.5.3),
on suppose que l'envoi et la réception de message ont lieu en même
temps. On n'a pas besoin d'un "buffer" intermédiaire (file d'attente)
dans ce cas. Ceci s'appelle aussi "rendezvous" et suppose une forte synchronisation:
l'opération combinée envoi-réception peut seulement
se produire si les deux parties (les processus émetteur et récepteur)
sont tous les deux prêts à faire leur part. En conséquence,
le processus émetteur peut avoir à attendre que le processus
récepteur soit prêt et vice-versa (le second cas se produit
déjà dans l'échange asynchrone en fait).
Le paradigme d'échange de message est souvent utilisé avec
un modèle de machine à états finis pour d'écrire
le comportement des processus. Les machines d'états de UML l'utilisent pour la communcation inter-processus
(avec un modèle de files sans bornes).
Partage de resources
Besoin de l'exclusion mutuelle
- L'exemple de deux usager qui mettent à jour simultanément les salaires des employer:
- Un administrateur augmente le salaire de tous les employee par 5% : salary = salary * 1.05;
- L'autre administrateur ajoute un bonus de 100$ au salaire de l'employee X: salary = salary + 100;
- Quels sont les résultats possibles pour l'employee X, si initialement il avait un salaire de 5000$.
- Transactions dans les banques
de données (exécutée entièrement ou pas du tout;
exécuté en parallèle avec d'autres transactions dans
un cédule sérialisable, c'est-à-dire comme si elles
étaient exécutées séquentiellement, dans un
certain ordre; doivent laisser la banque de données dans un état
consistant; unité de recouvrement dans le cas d'une panne (possiblement
d'une composante du système, dans la cas d'une banque de donnée
distribuée). Ces propriétés sont appelées ACID (pour "atomicity, consistency, isolation, durability").
La réservation de resources
Réservation de ressources, e.g. en se servant d'une sémaphore
(représentant l'état occupé ou non de la ressource)
- Note historique: En construisant ce qui était peut-être le premier
système d'exploitation d'ordinateur à supporter l'exécution concurrente
de plusieurs processus (applications) en 1965, Dijkstra (à Eindhoven en
Hollande) avait besoin de réaliser l'exclusion mutuelle pour l'accès aux
ressources partagées de l'ordinateur (principalement le CPU et mémoire)
par les processus concurrents. Il programmait en langage machine et
réalisait que, sur certains ordinateurs, le jeu des instructions
disponibles ne permettait pas la réalisation de l'exclusion mutuelle.
(Un tel ordinateur n'est donc pas apte à exécuter plusieurs applications
en parallèle.) Pour implanter l'exclusion mutuelle, il définissait une
instruction primitive (disponibles sur certains ordinateurs) qu'il
appelait sémaphore. Une sémaphore est associée à une ressource partagée, et elle est un objet contenant une variable entière cachée qui
est initialisée au nombre de processus qui pourraient accéder en
parallèle la ressource (donc normalement = 1) et qui offre deux
opérations: P ("réserver": tester si la variable est > 0 et alors la décrémenter
sinon mettre le processus en attente) et V ("libérer", c'est-à-dire
incrémenter la variable et laisser continuer un processus en attente
(s'il y en a) qui retournera alors de l'appel de l'opération P). Une
application doit appeler l'opération P avant d'accéder à la ressource et
appeler V après cet accès.
- Conclusions:
- La sémaphore est une primitive
très simple pour programmer et contrôler la concurrence.
- On ne peut
pas réaliser la concurrence avec des instructions de bas niveau qui sont
fait seulement pour l'exécution séquentiel de programmes; des primitives
spécifique à la concurrence sont nécessaire. (De même, on ne peut pas
réaliser des boucles ou des énoncés IF, si l'on n'a pas une instruction
dont le flux de contrôle dépend du test d'une variable.)
- Par contre, plus tard, Lamport a trouvé l'algorithme de la boulangerie (Bakery algorithm - see Wikipedia) qui réalise l'exclusion mutuelle avec des opérations de lecture et écriture sur des variables partagées (où l'écriture doit être atomique).
- Règles de réservation plus complexes: exemple d'une ressource
avec lecteurs et rédacteurs (plusieurs lecteurs simultanés
possibles s'il n'y a pas de rédacteur). Un exemple fameux est le
problème des philosophes à la table ("dining philosophers") proposé par Dijkstra (chaque philosophe, pour
manger, doit d'abord réserver les deux fourchettes à gauche et à droite;
il peut y avoir des conflits). Voici le code pour un philosophe qui est initialisié avec le paramètre i qui indique à quelle place il se trouve à la table.
- Blocage (deadlock)
- Conditions nécessaires: (1) exclusion mutuelle, (2)
"hold and wait" : en gardant une ressource, un processus peut demander une
autre, (3) pas de préemption, (4) attentes mutuelles (circulaires)
- Stratégies possibles à adopter face aux blocages:
- prévenir : éviter une des conditions ci-hautes
- éviter : s'organiser pour éviter une attente
circulaire en fournissant des informations nécessaires aux différents
processus. Une exemple est la réservation de ressources en deux phases : les ressources sont ordonnées, et chaque transaction doit d'abord
réserver toutes les ressources nécessaires (dans l'ordre croissant
des ressources) avant de commencer de les libérer.
- détecter et récupération : détecter l'occurrence d'un blocage en construisant l'arbre des dépendances
d'attentes; si détecté, il faut détruire le travail
amorcé par un des processus (e.g. avorter une des transactions
Le concept de moniteur
- Historique: 1967 Simula (premier langage OO, défini
par Dahl en Norvège); 1972 Pascal (défini par Wirth à
Zurich, Suisse); 1976 Concurrent Pascal (défini par Brinch-Hansen,
un danois émigré aux États-Unis) : ce langage combine
la simplicité de Pascal avec le concept de classe de Simula et introduit
le concept de processus concurrent qui se coordonnent par des ressources
partagées de type "moniteur".
- Un moniteur est un instance d'une classe avec
- une exclusion mutuelle des appels des méthodes (en
Java introduit par le mot synchronized)
- la possibilité d'utiliser à l'intérieur
du corps d'une méthode les opérations wait (pour libérer
l'exclusion mutuelle et attendre que d'autres processus entrent le moniteur
et changent les variables locales pour satisfaire la condition du wait ) et notify (exécuté juste avant le retour de la méthode
pour réveiller d'autres processus qui pourraient être en attente sur
un wait).
- Une sémaphore est un cas spécial d'un moniteur: elle a deux
méthodes, réserver (appelé V) et libérer (appelé P).
- En Java, chaque instance d'Object ou d'un sous-type (donc chaque instance d'objet)
peut être utilisé comme moniteur en utilisant le mot clé
synchronized et les méthodes wait et
notify (or notifyall) qui sont définies pour la classe Object.
La concurrence en Java (Lire dans le livre de Sebesta)
Exemples:
- Une file FIFO en Java avec des processus de production
et de consommation (voir livre de Sebesta). Voici une copie du programme Java: (a) la classe Queue (note: il y a un bug dans l'incrémentation des pointeurs, comme nextIn) et (b) les classes (sous-types de Thread) Producer et Consumer qui appellent une instance de classe
Queue (la ressource partagée), et, plus bas, le code Java qui crée une
instance de Queue qui sera passée comme paramètre aux instances
créées de Producer et Consumer.
- Note: Un exemple similaire est donné dans le tutoriel Java de SUN sous le titre "Guarded Blocks").
- Voici des exemples supplémentaires de programmes Java qui utilisent des sémaphores ou d'autres moniteurs.
Questions supplémentaires:
- Comment pourrait-on implementer les moniteurs de Java dans la machine virtuelle ? (supposez que vous soyez le concepteur de la machine virtuelle pour Java)
- Programmez l'exemple des lecteurs et rédacteurs en différentes versions (différentes priorités).
Initialement écrit: 22 mars 2003;
mise à jour: 19 mars 2004; révisions typographiques: 2005, 2008, 2009, 2010, 2011. 2013
{kind=link}
{kind=link}
{kind=link}